
PaperTrail: Research-Augmented Dataset Description Generation
Course Project for Natural Language Processing (Graduate Level)
Fall 2025
📂 GitHub Repository 📊 Interactive Description Viewer
Automated dataset description systems help researchers discover and evaluate datasets, but they typically rely solely on statistical profiling of the data itself—missing critical contextual information about collection methodology, intended use cases, and known limitations that appear in scientific literature.
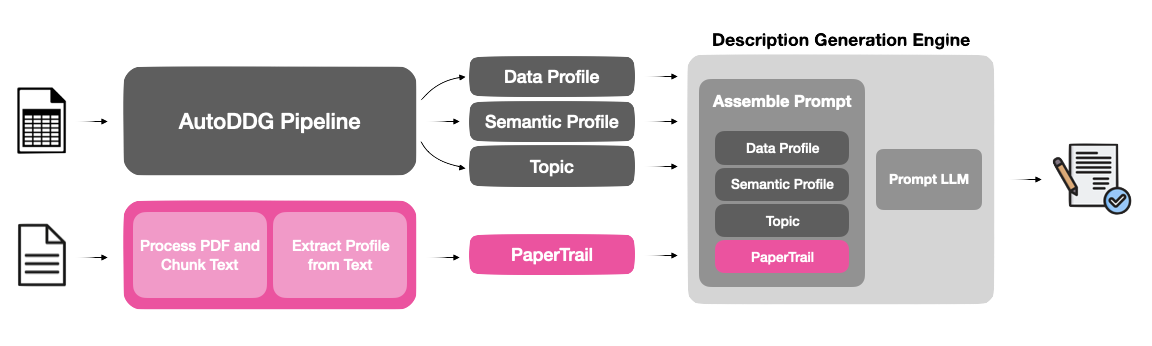
PaperTrail addresses this gap by extending the AutoDDG dataset description pipeline with a retrieval-augmented approach that extracts insights from research papers citing the dataset. When researchers publish work using a dataset, they often document methodological decisions, preprocessing strategies, and practical limitations—exactly the information other researchers need for informed dataset selection.
The Challenge
Scientific papers discuss datasets in unpredictable ways. Relevant information may appear in methods, results, or discussion sections; it may be explicit (“this dataset exhibits selection bias”) or implicit (reflected in preprocessing choices). The core technical challenge lies in identifying and extracting dataset-specific information while filtering out general methodological content unrelated to the dataset itself.
Technical Approach
I developed a three-stage pipeline that augments AutoDDG’s existing statistical and semantic profiling:
1. PDF Processing & Section Identification
I implemented a keyword-based anchor search that identifies paper sections explicitly referencing the dataset. The system tokenizes the dataset name, searches for chunks containing key tokens, then extracts context windows around these “anchor” sections. This approach outperformed LLM-based relevance scoring, achieving higher coverage (0.51 vs 0.45) while processing only 78.5% of paper length compared to 94.1% for the LLM method.
2. Profile Extraction
Using an LLM (Llama 3.1 8B), I extract structured information about research domain, usage patterns, data characteristics, and limitations from the identified sections. I explored three prompt design strategies—paragraph summaries, structured JSON schemas, and research decision support framing—with the research-oriented approach performing best.
3. Integration with AutoDDG
The extracted research profile is incorporated alongside AutoDDG’s data profile and semantic profile in the description generation prompt, enabling the system to produce enriched descriptions that combine statistical analysis with real-world usage context.
Evaluation & Results
My partner and I evaluated PaperTrail on 10 dataset-paper pairs from Zenodo spanning immunology, clinical medicine, biodiversity, genomics, and climate science. As for our metrics, my partner and I developed a custom coverage metric that measures presence of information across five dimensions (basic info, data characteristics, provenance, usage context, and quality/limitations). We also evaluated along with reference-based metrics (ROUGE, BERTScore) and LLM-based quality assessments:
- Coverage improved by 6.2% (strict) and 10.6% (lenient) over baseline AutoDDG
- Largest gains in provenance and usage context—precisely the dimensions that citing papers provide but repository descriptions typically omit
- Quality metrics remained stable: completeness (+4.5%), readability (+0.6%), conciseness (-2.8%)
- Reference-based metrics showed minimal change, reflecting that repository descriptions often lack the contextual information PaperTrail adds
The results demonstrate that research literature contains complementary information to statistical profiles, and that this information can be systematically extracted to produce more comprehensive, usage-oriented dataset descriptions.
Key Contributions
- Novel retrieval-augmented approach combining data profiling with scientific literature analysis
- Intelligent section identification using keyword-based chunking to locate dataset-relevant passages
- Open-source implementation released as an extension to AutoDDG
- Interactive evaluation viewer for transparent comparison of results (live demo)
- Curated evaluation dataset of 10 dataset-paper pairs with original author descriptions